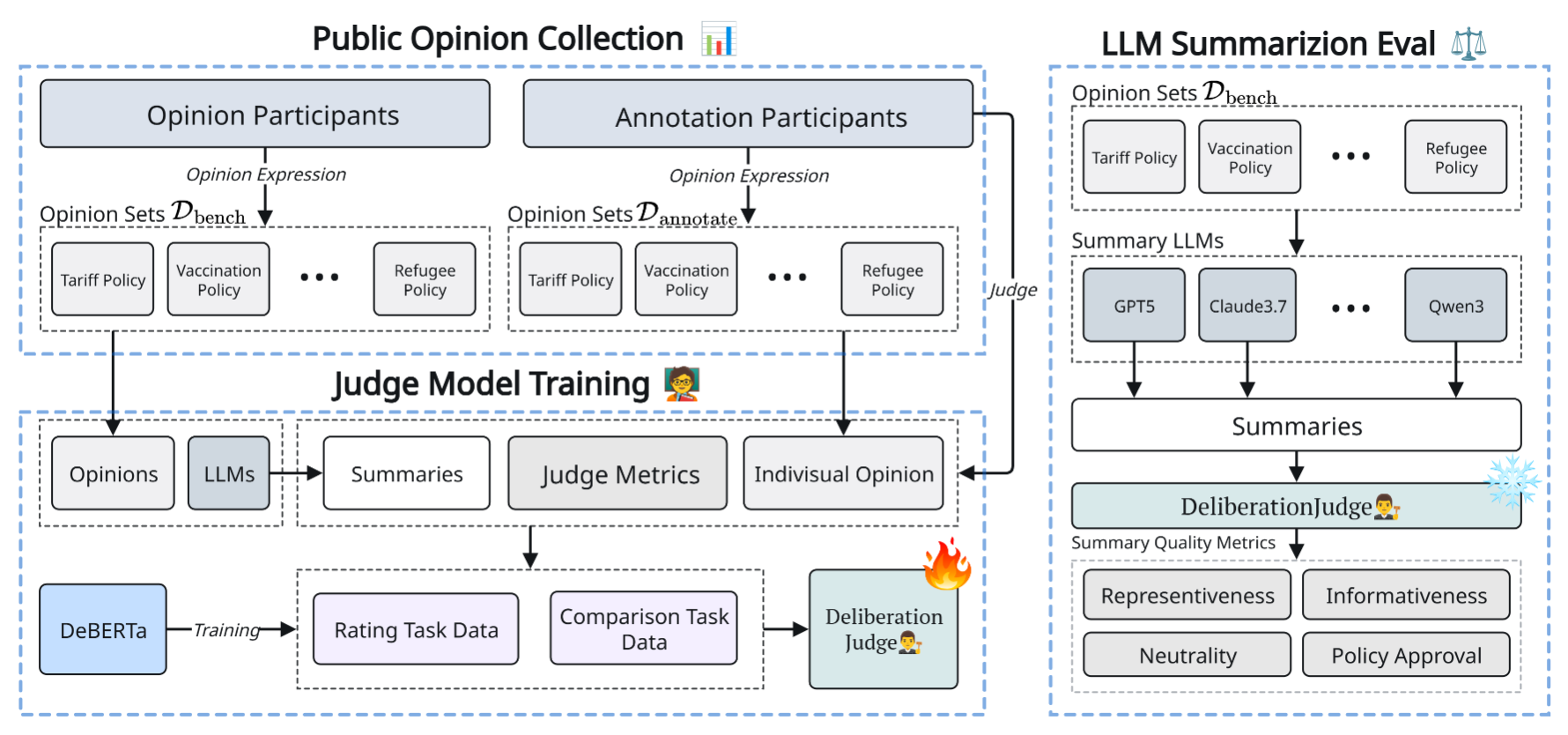
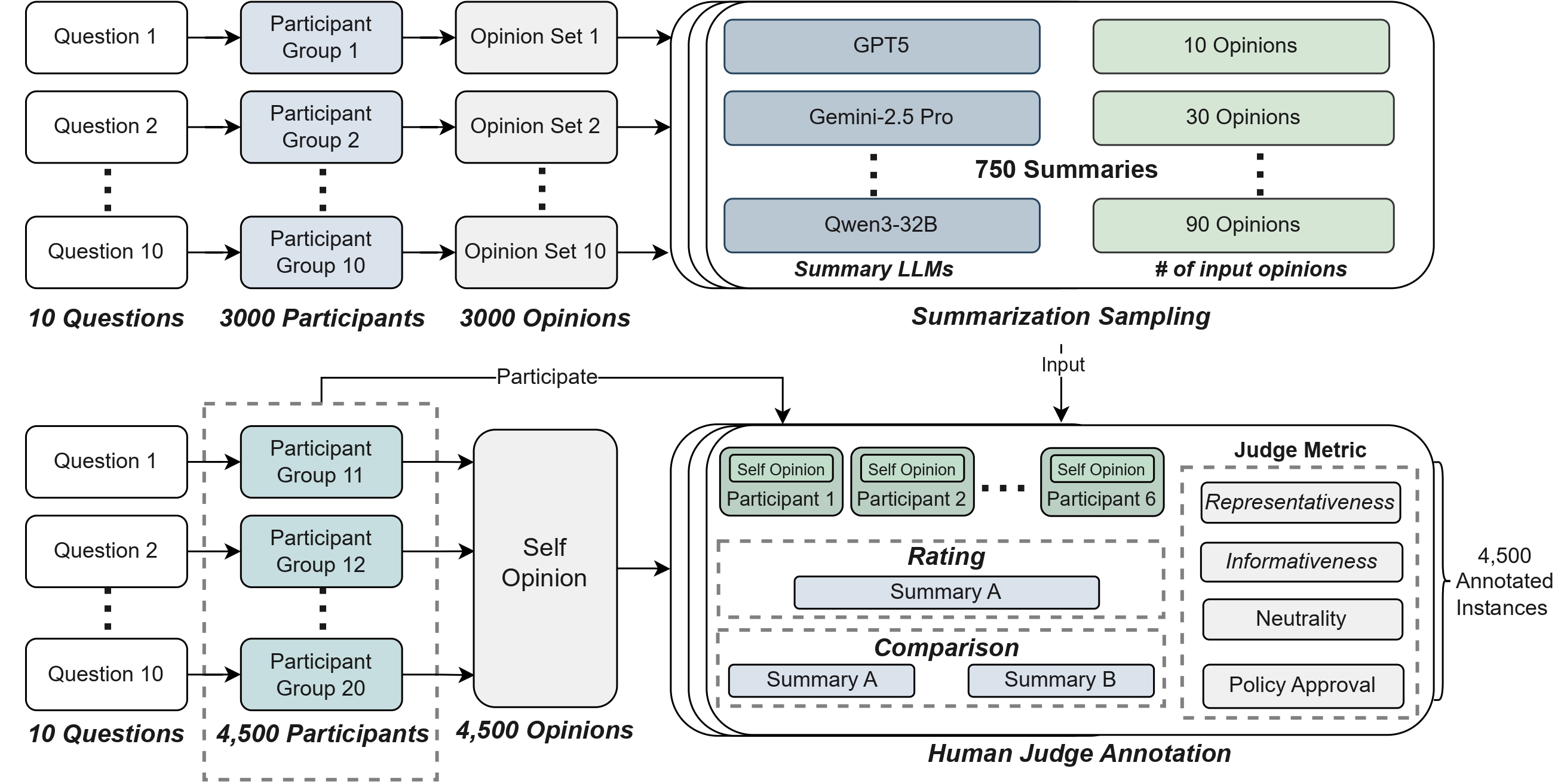
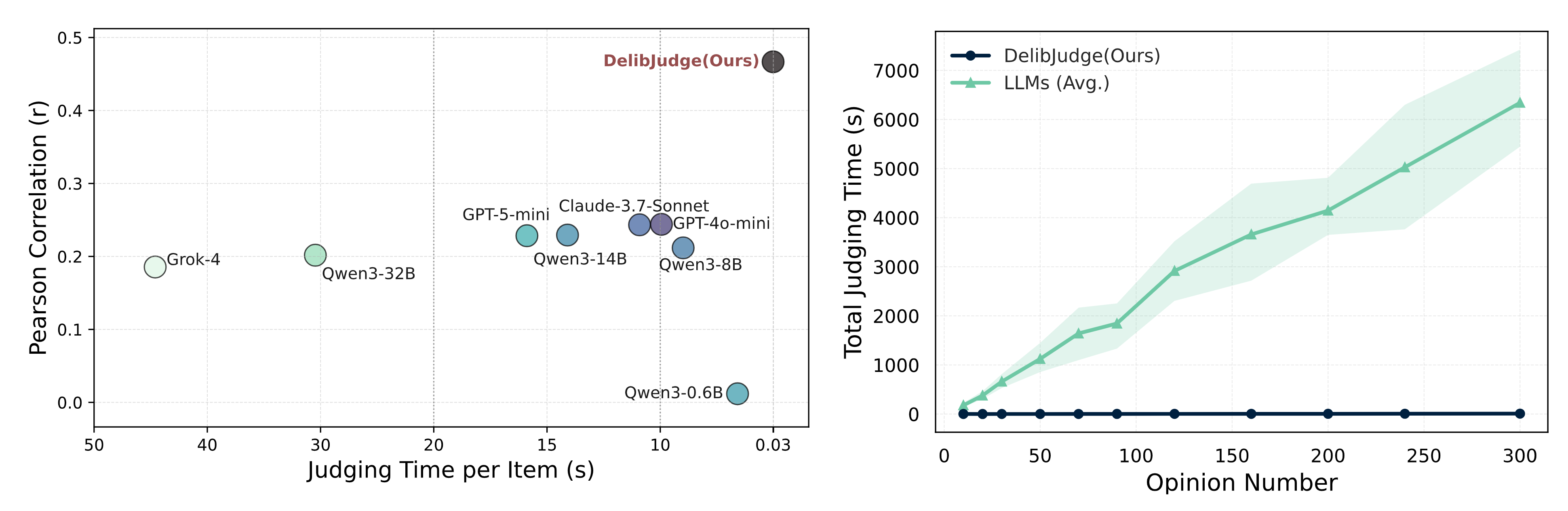
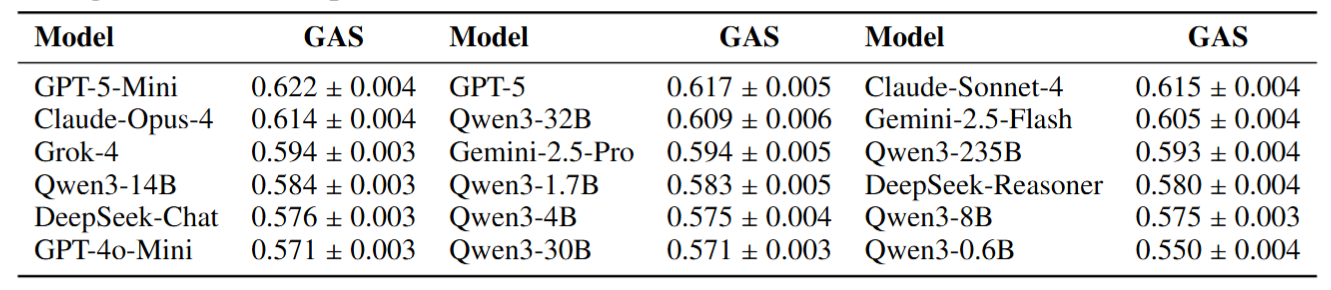
DeliberationJudge
Recent work has adopted pretrained LLMs as automated judges, but studies reveal systematic biases and instability rooted in their black-box nature and alignment limits. To improve reliability while retaining efficiency, we introduce
DeliberationJudge, a DeBERTa-based model fine-tuned on human judgments for deliberation summarization and used for automatic evaluation. We utilize the summary judgement dataset to fine-tune the language model.
The DeliberationJudge is trained with normalized labels from both rating and comparison tasks on a unified [0,1] scale. Formally, given a deliberation question \( q_i \), an annotator opinion \( o_i^{(j)} \), and a candidate summary \( S_{M,\tilde{O}_i} \), the judge encodes:
\[
[\texttt{[CLS]};\, q_i;\, \texttt{[SEP]};\, o_i^{(j)};\, \texttt{[SEP]};\,
S_{M,\tilde{O}_i};\, \texttt{[SEP]}]
\]
and outputs a four-dimensional score vector:
\[
\hat{\mathbf{y}} = \mathcal{J}_{\theta}\!\left(q_i,\, o_i^{(j)},\, S_{M,\tilde{O}_i}\right)
= \bigl(\hat{y}^{(\mathrm{rep})},\, \hat{y}^{(\mathrm{inf})},\, \hat{y}^{(\mathrm{neu})},\, \hat{y}^{(\mathrm{pol})}\bigr) \in [0,1]^4
\]
Here the [CLS] representation from the final encoder layer is passed through a hidden layer and a linear projection to produce the four regression outputs. Human annotations \( y^{\mathrm{raw}} \in [-1,7]^4 \) are linearly normalized to \( y \in [0,1]^4 \) for training stability. The model is trained with the Huber loss averaged across dimensions. At inference time, predictions remain in the [0,1] range and are used directly as summary scores.